
高速・高性能な推薦モデル!
今回は「Embarrassingly Shallow Autoencoders for Sparse Data」 という論文で提案されていた Easer と呼ばれる推薦モデルについてまとめたいと思います。このモデルはひじょ〜〜〜にシンプルなのにも関わらず、多くのデータセットで高い性能を発揮したすごいやつです。
できる限りわかりやすくこの推薦モデルのすごさについてまとめたいと思います。
Easer のここがすごい!
非常にシンプル!
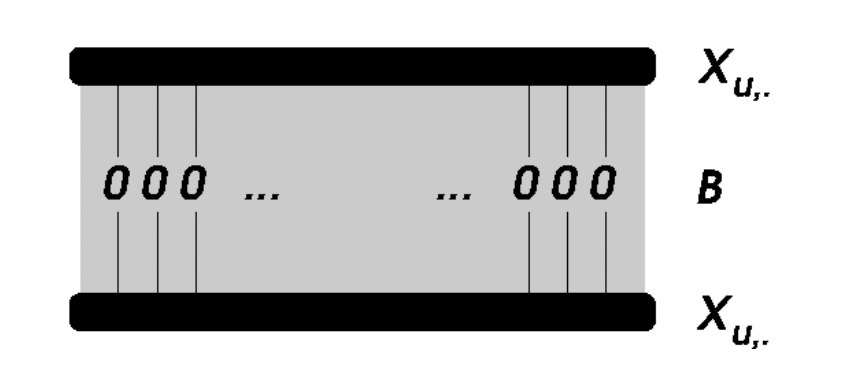
このモデルでは、これまでの多くのimplicit feedbackの設定[1]ユーザがどのアイテムにアクションしたか というような暗黙的な行動のみで推薦を作る問題設定で使われるのと同様の、ユーザxアイテム行列を入力にします。ユーザxアイテム行列は、例えばuser iさんが item j に対してアクションした時に行列のi行j列の要素が1になるような行列のことです。
ここで、このモデルが持っているパラメータを紹介します。
- Item数 x Item数のサイズの行列 B
- L2正則化のパラメータ λ
以上だ!!
めちゃめちゃシンプルです。
この行列を使って、あるuser uさんにアイテム j をレコメンドするときのスコアを以下のように計算します。
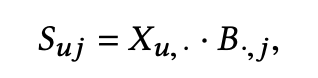
学習・推論時間が圧倒的に早い!
持っているパラメータが少なく、学習・推論の演算(行列 B の学習方法については「手法の深堀り」の章で記述)も単純なので、圧倒的に早くモデルの構築と利用が可能です。
論文では SLIM (Sparse Linear Method)[2]https://takuti.me/ja/note/slim/ がわかりやすいです などの手法と比較されており、以下のデータセットで評価されていました。
- Netflix Prise (ユーザー数463,435人、映画本数17,769本、インタラクション数約5,700万回。)
- SLIM: 並列でのgrid探索で最適なパラメータを見つけるのに約2週間 [3]https://arxiv.org/pdf/1802.05814.pdf にて検証されている。MSDの実験も同様。
- Easer: 学習が2分以内で終わる (パラメータチューニングを考えると、探索する設定の数だけ乗する必要があるが、探索すべきパラメータはλのみ)
- MSD(Million Song Dataset)[4]http://millionsongdataset.com/
(ユーザー数571,355人、楽曲数41,140曲、インタラクション数約3,400万回。)- SLIM: 時間がかかりすぎて現実的な時間では終わらない
- Easer: 学習が20分以内に終わる
なお、上記の学習はメモリ64GB、16個のvCPUを持つAWSインスタンス1台での学習時間だそうです。
これまでの推薦モデルと比較して、圧倒的に高速なことがわかります。
高い品質の推薦が作れる!
手法がシンプルで学習・推論時間が短いにも関わらず、高い品質のレコメンドを作ることが可能です。
論文内では3種類のデータセットで評価されており、いずれのデータセットでも他の手法(線形モデル、深層学習ベースのモデル)と比較して高い性能を示していました。
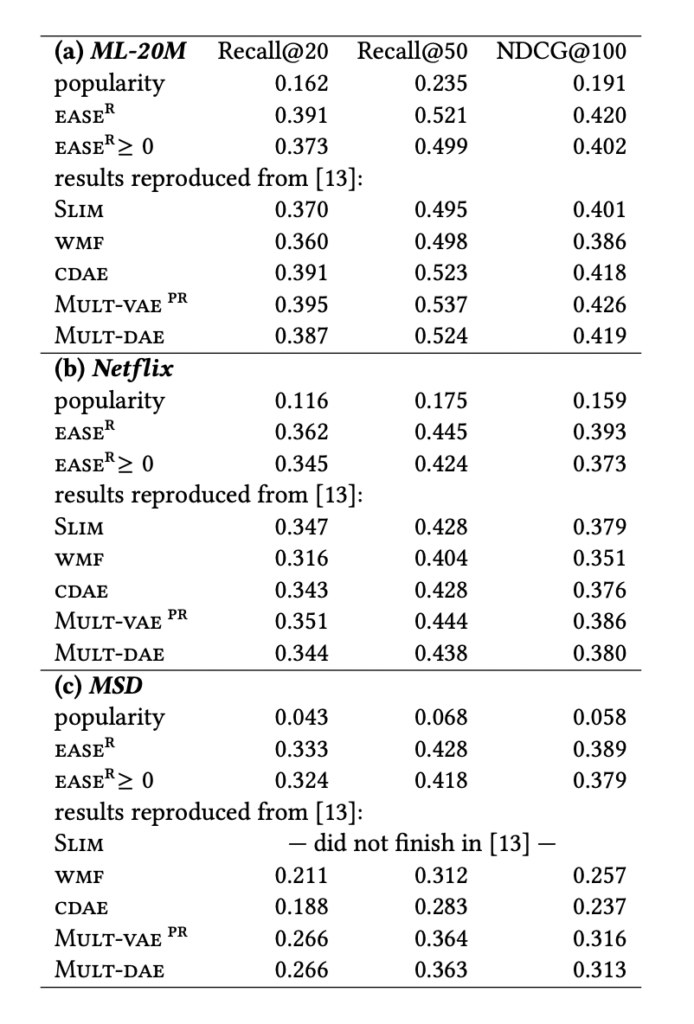
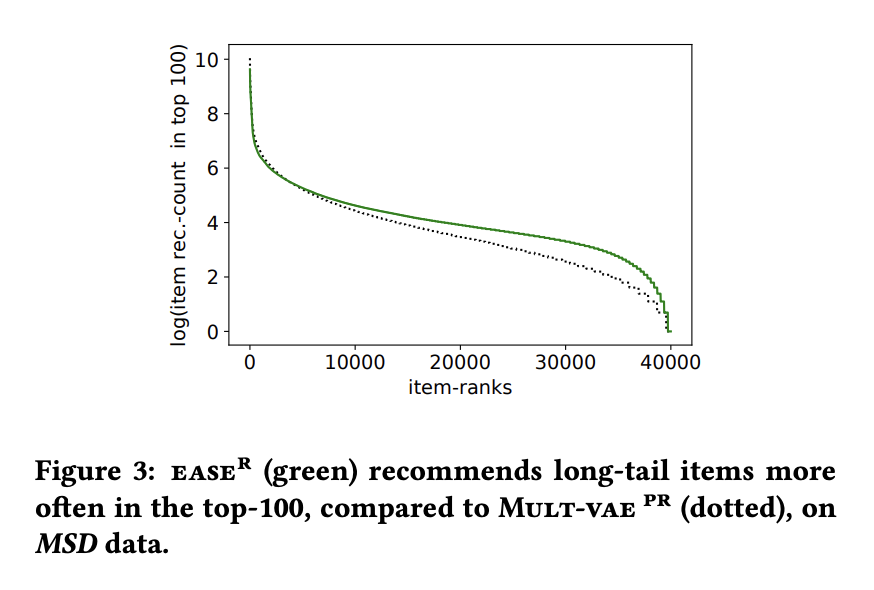
MSDデータでは、深層学習ベースのモデルと比較してロングテールのアイテムをより多くレコメンドできていたようです。他の手法と比較して、多様性がありユーザごとに最適なレコメンドを出すことができていそうです。
実装がとても簡単!
実装は、以下のリポジトリで公開されています。
モデルの学習部分の実装はなんとたったの6行です。(!?)
G = X.T.dot(X).toarray()
diagIndices = np.diag_indices(G.shape[0])
G[diagIndices] += lambda_
P = np.linalg.inv(G)
B = P / (-np.diag(P))
B[diagIndices] = 0シンプルすぎて笑ってしまいますね
手法の深堀り
ここまで、Easerのすごいところをお話ししてきました。
ここからは手法についてさらに掘り下げた説明を記したいと思います。
できる限り論文の内容に基づいて説明をしたいと思いますが、僕の勘違いによって誤った説明となっている可能性があります。正当性は保証できませんのでご了承ください。興味がある方はぜひ元論文を読んでみてください!
著者の説明
この論文の著者は、Netflixに所属している Harald Steck さんです。長い期間推薦システムについて研究されている方です。自分が知っていた論文だと、2018年に発表された「Calibrated Recommendations[5]https://dl.acm.org/doi/pdf/10.1145/3240323.3240372」(ユーザが特にたくさん閲覧したカテゴリのアイテムばかり推薦してしまう問題を解決しましょう、みたいな話) もこの方が著者だということを知り驚きました。
目的関数
Easerの目的関数は以下のようになります。
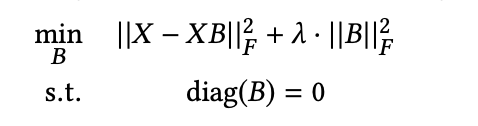
- Xはユーザxアイテムの行列、Bはアイテムxアイテムの重み行列を表します。
- ||・||F はフロべニウスノルムを表します。フロべニウスノルムは行列の全要素をそれぞれ2乗し和を取ってrootを取ったものです[6]https://manabitimes.jp/math/1284。 = 行列の全成分を横に並べたベクトルのL2ノルム
- 右項はL2正則化項になります。λの値は実験の結果200~1000と、データセットによって大きく異なったそうなので、実際に使う場合はチューニングが必要そうです。
- Bの対角要素を0にする条件を入れるのが非常に重要です。これによって、「同じアイテムは似ている」という自明な学習がされることを防ぎます。これは先行研究である SLIM で用いられているテクニックになります。この制約条件が入っていることで、Easerは 「隠れ層がなく、同じ次元につながる重み行列の要素が0のAutoEncoder」という解釈ができます。これが論文のタイトルである「Embarrassingly Shallow Autoencoders(恥ずかしいほど浅いAutoEncoder)」の由来です。
- 目的関数ではXとXBの間のsquare lossが用いられているが、これによりBが閉形式の解を持つようになる。閉形式 -> 定数、一つの変数x、四則演算、n乗根、指数と対数で解析的に表現される式[7]https://minus9d.hatenablog.com/entry/20130624/1372084229。つまり非常に簡単な式でBを導出することができるようになる。これが学習が早い理由。
- 目的関数ではsquare loss以外を使うことも可能で、そうすることにより精度が向上する可能性があるが、学習時間も増大する可能性がある。
閉形式について
論文内ではBを求める閉形式の導出が示されていましたが、僕の数学力では正しく解釈、説明することが難しいため、説明は省略します…。
式変換の結果、以下の通りとなります。
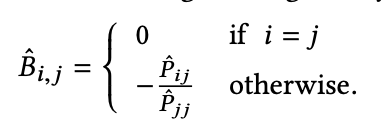
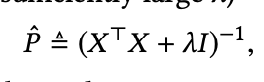
アルゴリズム
Bを計算するためのアルゴリズムは、前述したコードで表されます。
G = X.T.dot(X).toarray()
diagIndices = np.diag_indices(G.shape[0])
G[diagIndices] += lambda_
P = np.linalg.inv(G)
B = P / (-np.diag(P))
B[diagIndices] = 0Bを計算した後に、最後の行で対角要素を0にしています。
実装的に、グラム行列Gのサイズ(アイテムxアイテム)がXに含まれるユーザインタラクション数より小さい場合は、非常に効率的に計算が可能になる。
また、グラム行列Gの計算は非常に高価だが、この部分は前処理としてビッグデータ処理環境(sparkなど)で事前に計算しておく運用が可能になる。
その他特筆すべき点
- このモデルはAutoEncoderベースと近傍ベースの手法の利点を兼ね備えたモデルと解釈できる。
パラメータ行列Bがアイテム間の類似度を表すと解釈できるため。 - パラメータ行列Bでは、アイテム間の類似度だけでなく、アイテム間の非類似度(負の値)も表すことができることが、Easerのモデル性能に大きく寄与している。Bの要素を非負の値に制限したした時の性能は総じて低くなることがわかった。(前述の表の Easer ≧ 0の結果)
- 学習は、グラム行列Gがメモリにさえ乗れば非常に高速に処理ができるが大規模なデータセットな場合はその分大きなメモリが必要になる。(アイテムxアイテムの行列の保持が必要) なので、超大規模なデータセットに適用したい場合は、メモリがごついマシンを用意する必要がありそう。
まとめ
今回は非常に高速・高性能なEaserモデルについて紹介いたしました。
最先端な推薦システムの手法は、深層学習ベースの物が多く、非常に複雑で膨大な計算リソースが必要になることが多い中で、ここまでシンプルで性能が良いモデルが出てくるのはシンプルにすごいと思いました。
実プロダクトでは推薦の設定ごとに最適なモデルが異なってくると思いますが、ここまでシンプルなモデルならば、いわゆる「強いベースラインモデル」として初手で試すのも良さそうですね!
今後は何らかのデータセットで実際にこのモデルを動かしてみたいと思います。
こちらのブログでもEaserについてわかりやすく紹介されているので、ぜひご覧ください!(PyTorch実装あり)

References
| ↑1 | ユーザがどのアイテムにアクションしたか というような暗黙的な行動のみで推薦を作る問題設定 |
|---|---|
| ↑2 | https://takuti.me/ja/note/slim/ がわかりやすいです |
| ↑3 | https://arxiv.org/pdf/1802.05814.pdf にて検証されている。MSDの実験も同様。 |
| ↑4 | http://millionsongdataset.com/ |
| ↑5 | https://dl.acm.org/doi/pdf/10.1145/3240323.3240372 |
| ↑6 | https://manabitimes.jp/math/1284 |
| ↑7 | https://minus9d.hatenablog.com/entry/20130624/1372084229 |


コメント