

渡辺徹太郎 著
なぜ?がわかるデータ分析システム開発の教科書
今回は ビッグデータ分析のシステムと開発がしっかりわかる教科書 を読んだので、それについて見所や感想などをまとめたいと思います。
ゴールデンウィークなので、これまで積んでいた本を消化中です!
読もうと思った背景、期待したこと
普段は何気なくデータの分析や可視化、モデリングを行っていますが、そのデータをどのように集めて蓄積しているかはとてもざっくりとしたイメージしか持っていませんでした。特に、データ収集、蓄積、活用の一連の流れであるデータパイプラインの、「収集」に関わる技術の理解が鮮明でないという自覚がありました。
データを扱う職種に勤める身として、これら一連の流れをある程度把握しておくべきと考えて本書を手に取りました。
勉強になったこと、面白かったこと
全体 -> 個別の詳細 という流れで理解しやすかった。
Amazonのサンプル画像より引用
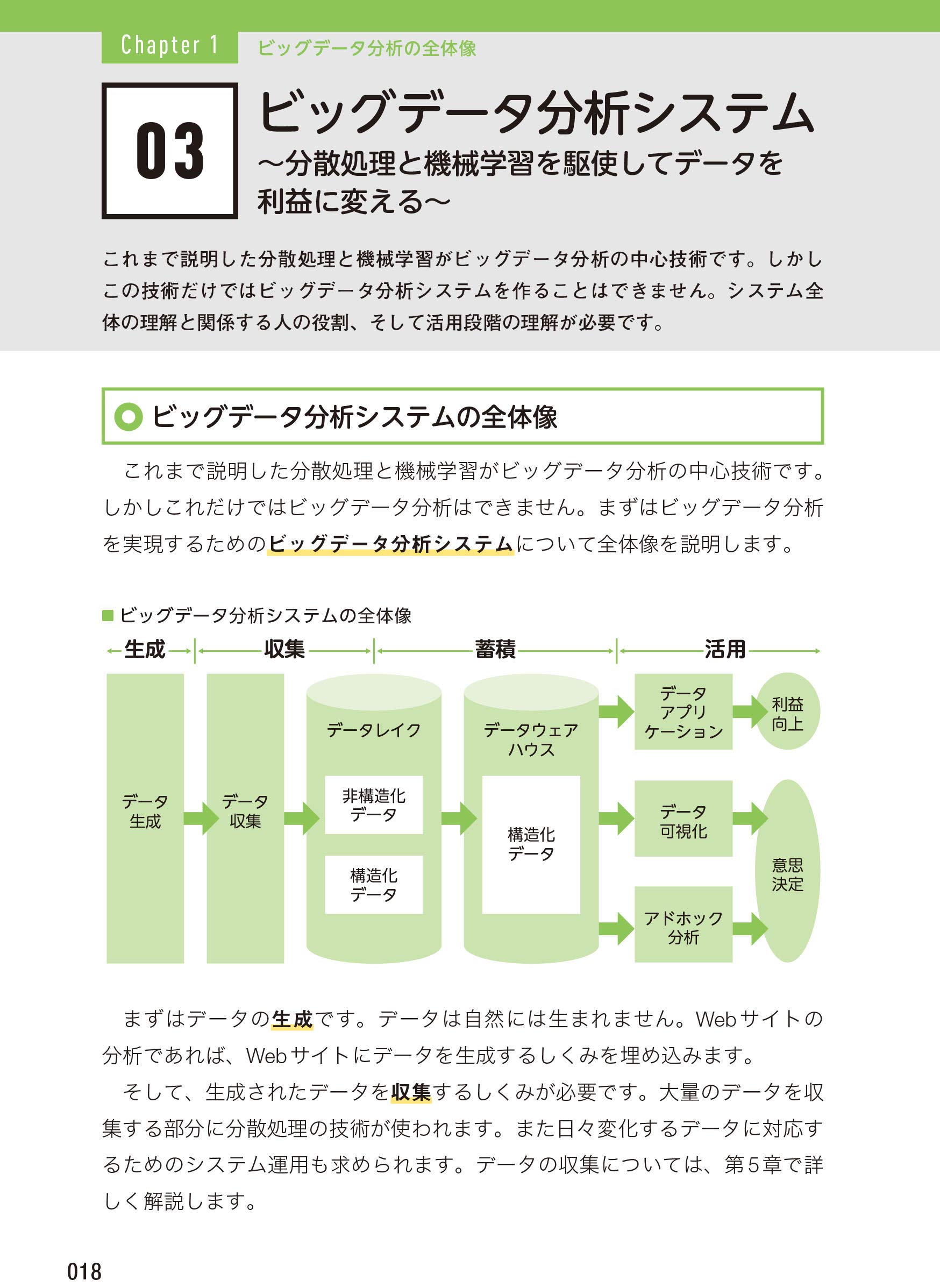
ビッグデータ分析システム
こちらはChapter1に出てくる、ビッグデータ分析システムの概要図です。データを収集してからそれを活用するまでに必要なことが示されています。
この図は僕が持っているビッグデータ分析システムのイメージと完全に一致していたため、その点は安心しました。このような全体像の説明から入り、各Chapterでこれらの詳細について解説していく流れとなっていました。この流れは非常に理解がしやすく良かったです。後のChapterではこの図をさらに詳細にした図も登場しさらに理解が深まりました。
「自分はデータ生成、収集、データレイク周りがよくわかっていないな」と言語化ができ、引き続き読み進めるモチベーションになりました。
なぜ?の説明がしっかりされている
それぞれのChapterでは前述の図の要素ごとの解説がされていますが、どれも「なぜこれが必要なのか」の理由をしっかりと説明されていて、内容がすんなりと頭に入ってきました。
以下の内容はどれも、「説明してください」と言われると自信がないことでしたが、本書を読むことで説明できるようになりました。
- なぜデータを蓄積する際はデータレイクとデータウェアハウスに分けるのか
- データのバッチ集計とストリーム集計のメリット・デメリットはなにか
- データレイクにデータを蓄積する前に使う分散キューの特性と注意点はなにか
- 管理すべきメタデータの種類はなにか
図が多くどれもわかりやすい
前述でビッグデータ分析システムの概要図が登場しましたが、本書はそれ以外にもたくさんの図表が登場します。どれもが非常にわかりやすく、理解のための助けとなりました。
この図表の多さとわかりやすさは、この領域に知識がない人でも抵抗なく学ぶことができることにつながるなと感じました。
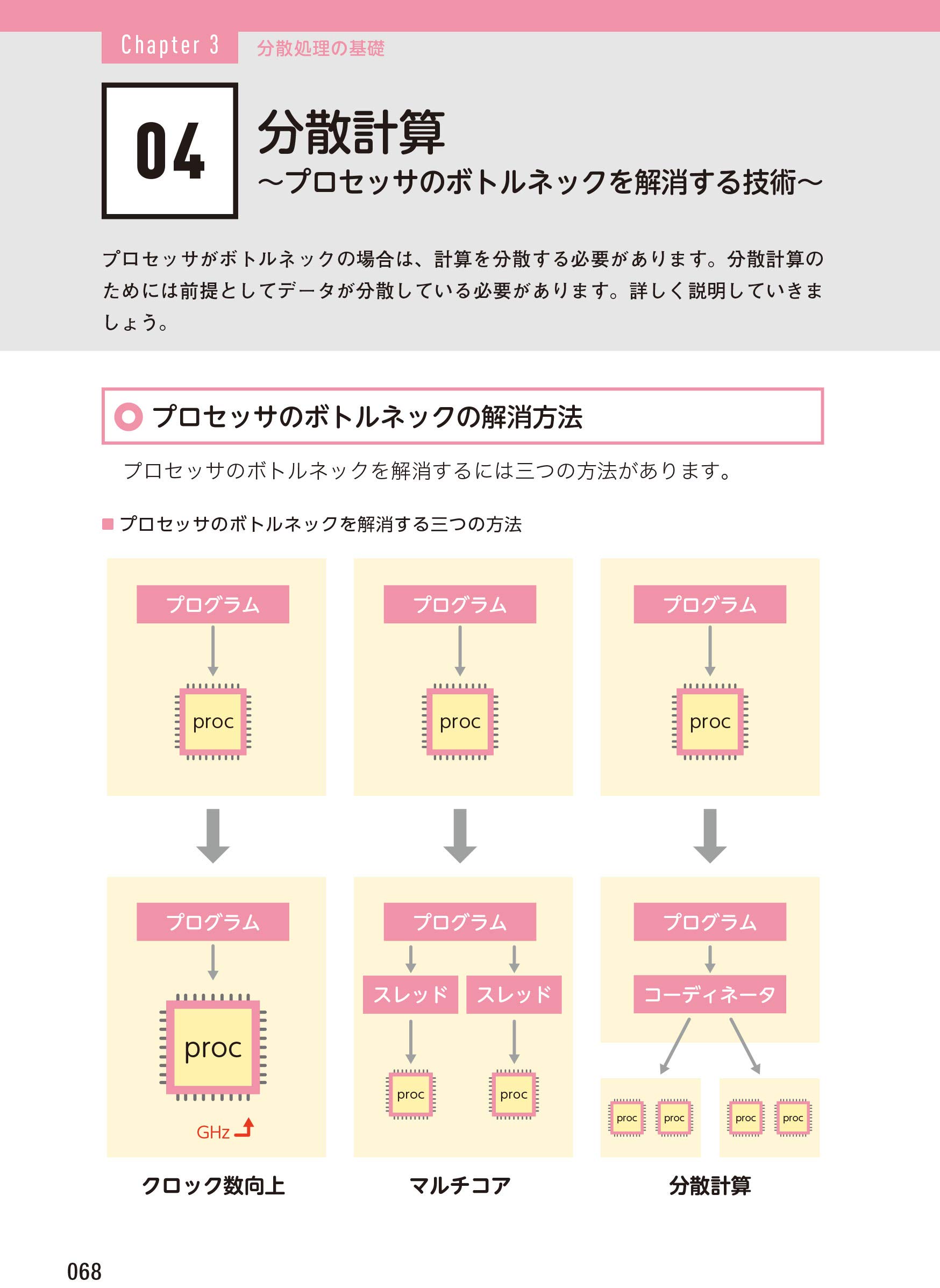
Amazonのサンプル画像より引用
なぜ分散処理が必要なのかについての説明に使っている図
運用時に注意するべき点までカバーしている
このようなビッグデータ分析システムを運用していて発生するトラブルの多くは、そのような場面になって初めて発覚するようなことばかりでした。(これは単に自分の勉強不足ですが…)
本書では、ビッグデータ分析システムの各領域を運用する際の注意点まで網羅されており、とても良かったです。
特に、以下のような内容は自分にとって大変勉強になりました。
- 分散ストレージを扱うときは整合性レベルに注意する
- オンプレミスとクラウドを繋ぐネットワークの帯域に注意する
- サイエンスチームとエンジニアリングチームの役割分担(どこに責任を持つか)
- データ構造(DBのスキーマなど)を変更する時にどのような手順を踏むべきか
残念だったこと
特に残念な点は見当たりませんでした。
「データ分析システムにこれから携わる初学者が、いち早くその全容を捉えるための書籍」という目的の本として、とてもよくできていると感じました。
強いてあげるとするば、自分が購入したのが初版のものだったせいか、脱字がいくつか見られたことぐらいです。
こんな人におすすめ
この本は以下のような人におすすめしたいと思いました。
- 将来ビッグデータ分析の業務に携わりたい学生さん
- ビッグデータ分析の領域に興味がある他領域のエンジニアさん
まとめ
ビッグデータ分析のシステムと開発がしっかりわかる教科書を読んでみた感想などをまとめました。
データ分析に必要な技術が広く学べる入門に最適な一冊だと感じました。
また、自分が学生だった頃に読んでおきたい本だったなと感じました。
読んで良かったです!


コメント